
Glassdoor is one of the most popular jobs posting websites.
Glassdoor has many job postings, salary and company insights!
As a result, they contain valuable job data that can be used for competitor analysis or for your own research and study.
We are ParseHub, and today we will go over how to scrape Glassdoor data with a free web scraper. With this knowledge, you’ll be able to extract data related to job listings such as companies that are hiring, roles in demand, average salaries and more.
To do this, we will use ParseHub, a free web scraper that can easily tackle this task. You can download it for free through the link in the description or at ParseHub.com
How to scrape Glassdoor
Now, it’s time to get into the nitty-gritty of things. Here’s how to scrape data from Glassdoor.
- Make sure to download and install ParseHub for free. Boot it up and click on New Project.
- You now should enter the list of job postings to scrape. For this example, we will scrape the results page for “Marketing” jobs in Toronto. Enter the URL and the site will now load inside the app.
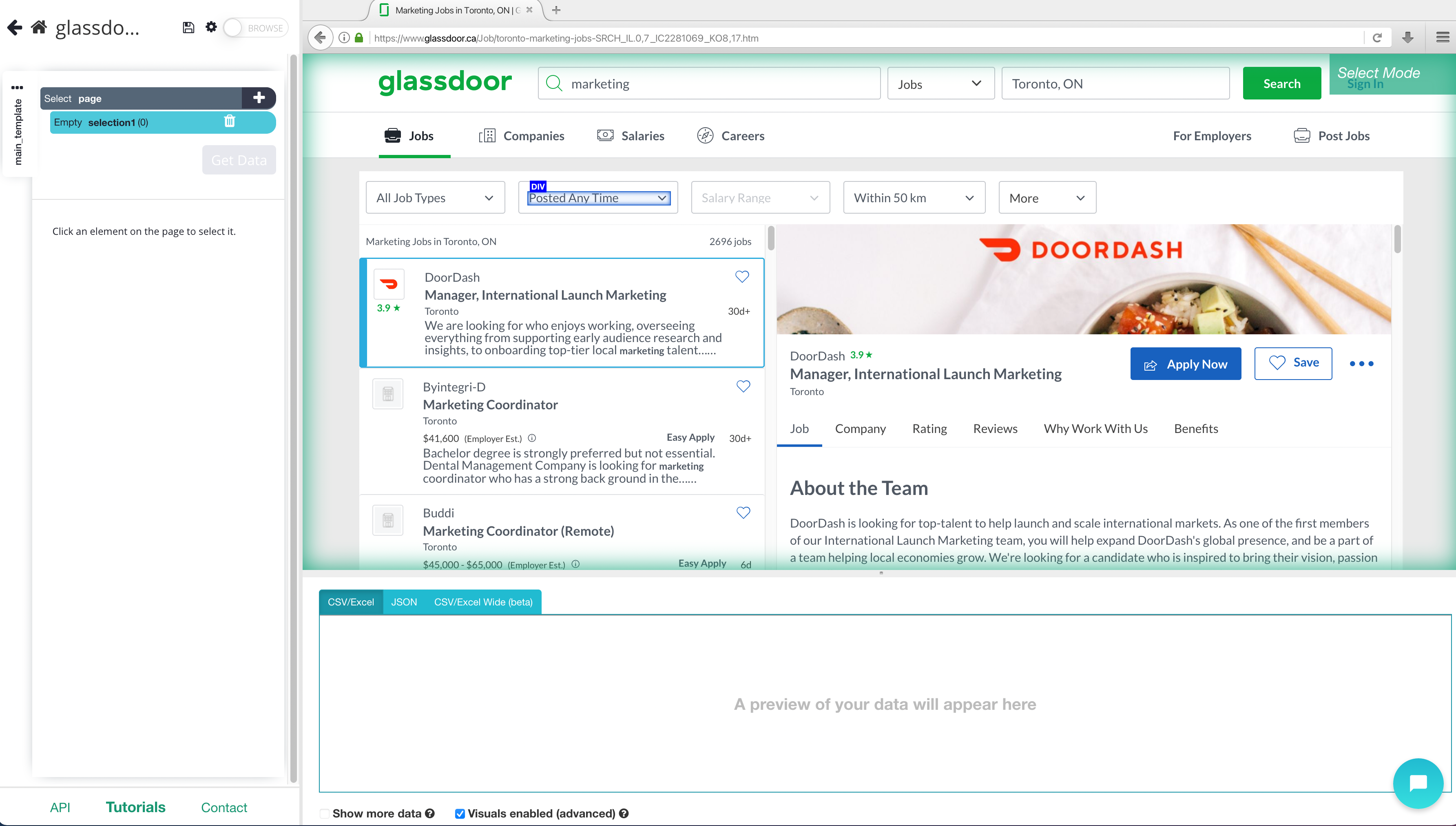
Scrape Job listings
Now it’s time to set up your web scraping project in ParseHub.
- Start by clicking on the title of the first job listing on the page. It will be highlighted in Green to indicate that it has been selected.
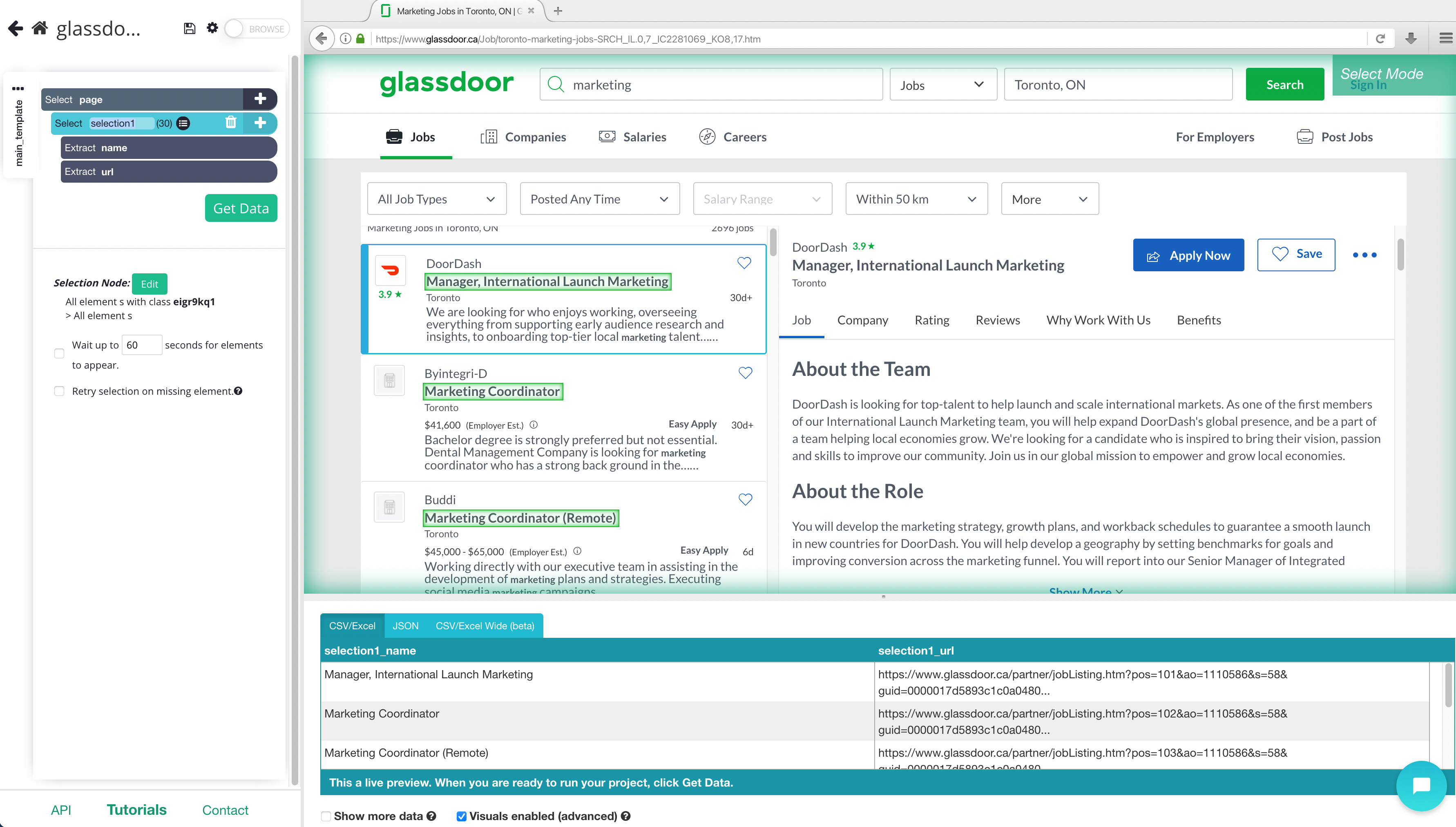
2. The rest of the titles will be highlighted in yellow. Click on the second one on the list to select them all. In the left sidebar, rename your selection to listing.
3. Now, Click on the PLUS (+) sign next to your listing selection and choose the “Relative Select” command.
4. Using the “Relative Select” command, click on the title of the first listing on the page. Then, click on the name of the company above it. An arrow will appear to show the association you’re creating. You might have to repeat this step with the second listing as well to fully train the scraper. In the left sidebar, rename your selection to company.
5. Repeat the previous steps to also pull the company’s location and listing salary. Rename your selection accordingly. Your project should now look like this:
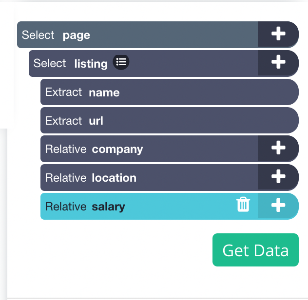
Adding pagination to your project
ParseHub is currently only extracting the details we’ve selected from the first page of search results. We will now set it up to extract data from further pages of search results.
- Click on the PLUS(+) sign next to your page selection and click on the “next page: link at the bottom of the page. Rename your selection to next.

2. Click on the Expand icon next to your next command.
3. Delete both extractions below the next command.
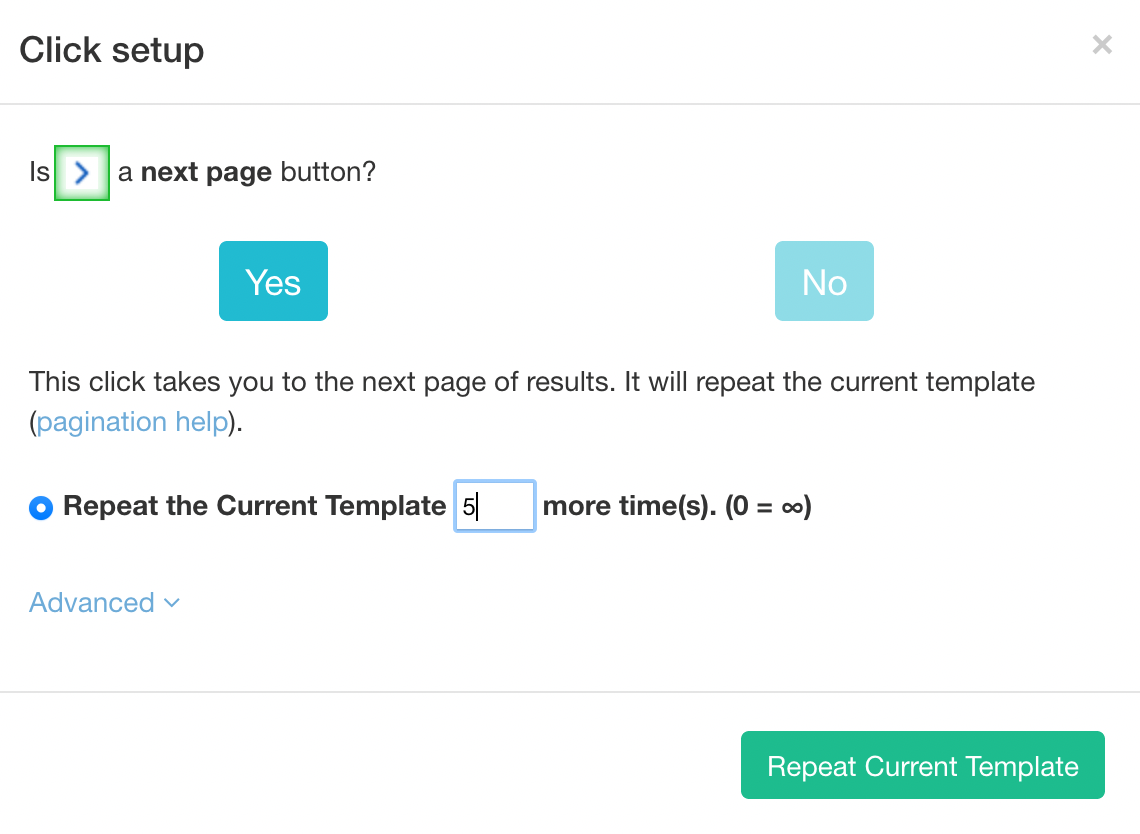
4. Click on the PLUS(+) sign next to the next command and choose the “click” command.
5. A pop-up will appear asking you if this is a “next page” link. Click on Yes and enter the number of times you’d like to repeat your scrape. To scrape 5 pages, we will need 4 repetitions.
Running your scrape
You can now run your web scraping project and download the data you have selected.
To do this, click on the green “Get Data” button in the left sidebar. Here you can choose to Test, Run or Schedule your scrape project.
For larger projects, we recommend running a test scrape. In this case, we will run it right away.
Closing thoughts
After your run has finished. You will be able to download it as a CSV or JSON file.
You will now have access to all the employment data you requested.
If you run into any issues while setting up your project, make sure to reach out to us via the live chat on our site. We’ll be happy to assist you through your project.
You can learn how to scrape another job listing website like indeed here
Happy Scraping!