
Good old HTML tables.
At some point, most websites were fully made via HTML tables.
Nowadays though, you might be interested in scraping data from an HTML table on to an excel spreadsheet or JSON file.
A web scraper can help you automate this task as copy/pasting usually messes up the formatting of your data.
Web Scraping HTML Tables
For this example, we will use ParseHub, a free and powerful web scraper to scrape data from tables.
We will also scrape data from Wikipedia for this example. We will scrape data on Premier League scores from the 1992-1993 season.
How to Scrape HTML Tables into Excel
Now it’s time to get scraping.
- Make sure to download ParseHub and boot it up. Inside the app, click on Start New Project and submit the URL you will scrape. ParseHub will now render the page.
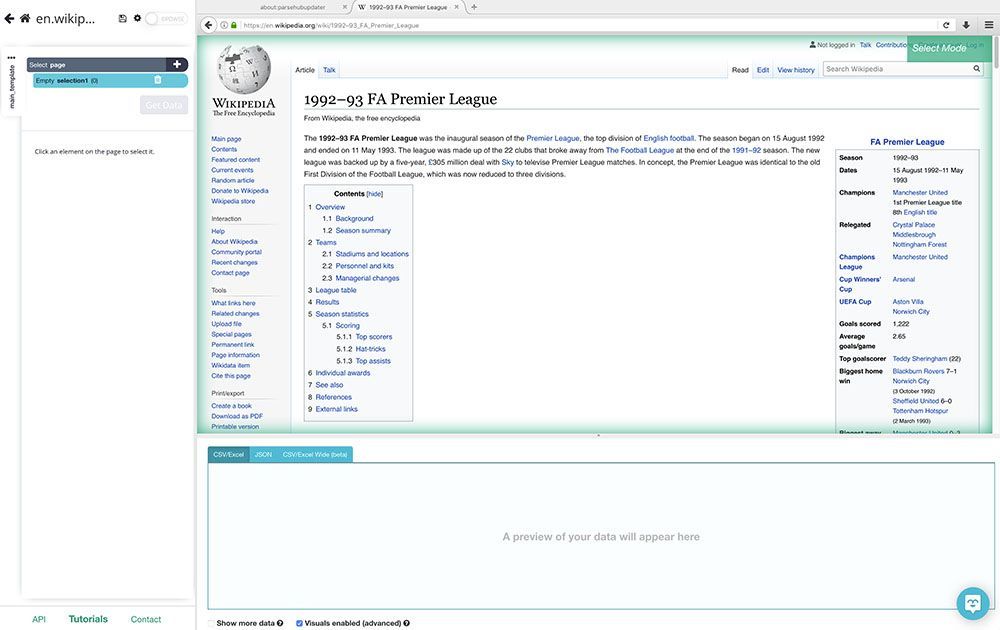
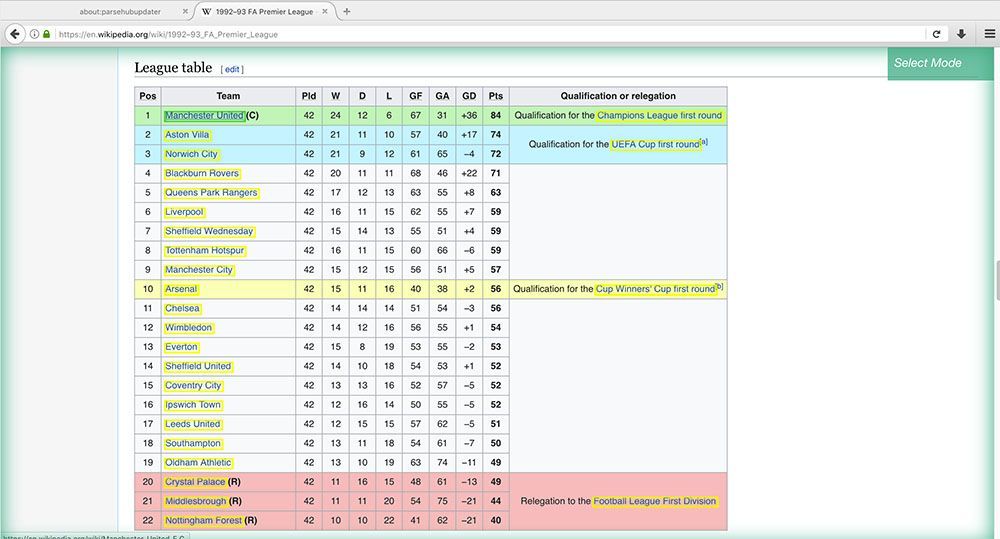
- First, we will scroll down all the way to the League Table section of the article and we will click on the first team name on the list. It will be highlighted in green to indicate it has been selected.
- The rest of the team names will be highlighted in yellow, click on the second one on the list to select them all.
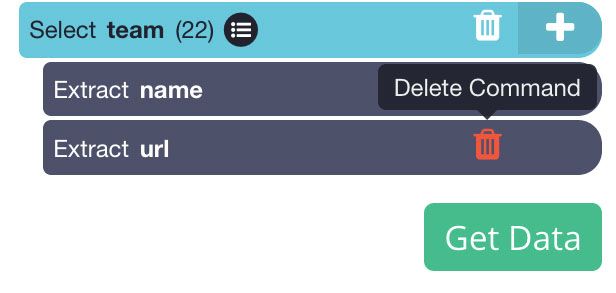
- On the left sidebar, rename your selection to team. Since we just want the data on the table, we will expand the selection and remove the URL extraction since we are not interested in this.
- Now we will start extracting the rest of the data on the table. To do this, start by clicking on the PLUS(+) sign next to your team selection and choose the Relative Select command.

- Using this command, click on the name of the first team on the list and then on the number beside it. An arrow will appear to show the association you’re creating.
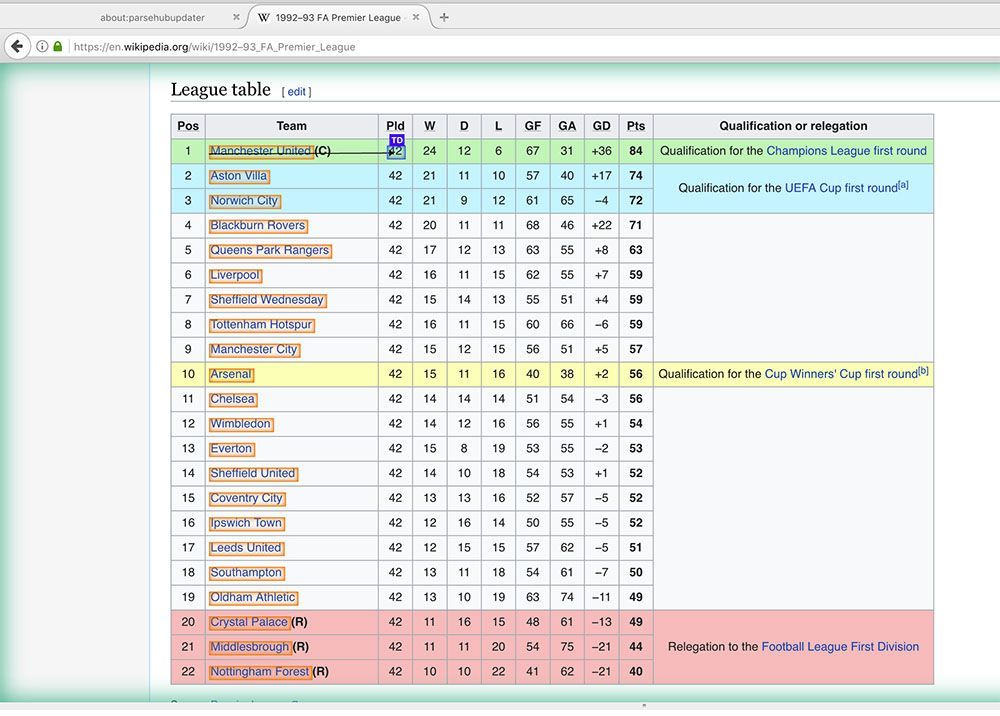
- Rename your Relative Select command to played. Now, repeat steps 5-7 to pull each column of data on the table.
Once you’ve added every column, ParseHub can now scrape the entire table into an Excel sheet.
Running your scrape
To run your scrape job, click on the green Get Data button on the left sidebar.
Here, you will be able to run your scrape job, test it or schedule it for later.
For longer scrape jobs, we recommend testing your scrape jobs to guarantee they are working correctly.
In this case, we will run it right away. Now ParseHub will go off and collect all the data we selected.
Once your scrape is complete, you will be able to download the data as an Excel or JSON file.
Closing Thoughts
You now know how to scrape HTML tables from any website.
However, we know that not every website is built the same. If you run into any issues while setting up your project, reach out to us via email or chat and we’ll be happy to assist.
Interested in scraping more than one page worth of tables? Check out our guide on scraping Wikipedia where we do just that!
Happy Scraping!