
Beautiful soup can be an effective method of extracting online data. But using beautiful soup can be intimidating if you don’t know what you’re doing or where to start!
While there is no perfect method for web scraping as everyone will have their preference, we’ll teach you how to web scrape without beautiful soup. You’ll need an automated web scraper to do the job.
But first, let’s explain what is beautiful soup.
What is beautiful soup?
Beautiful Soup is a Python library for getting data out of HTML, XML, and other markup languages. It’s an HTML Parser that is used for web scraping. Beautiful soup helps separate content from a web page to be extracted and then saved for later.
While using beautiful soup is a great skill to learn, we want to offer another skill that we think you’ll enjoy and that’s using an automated web scraping tool. While there are many web scrapers out there, we think you’ll enjoy ParseHub!
It’s free to download, easy to use, cloud-based scraping and powerful. You can download ParseHub for free
Web scraping without beautiful soup
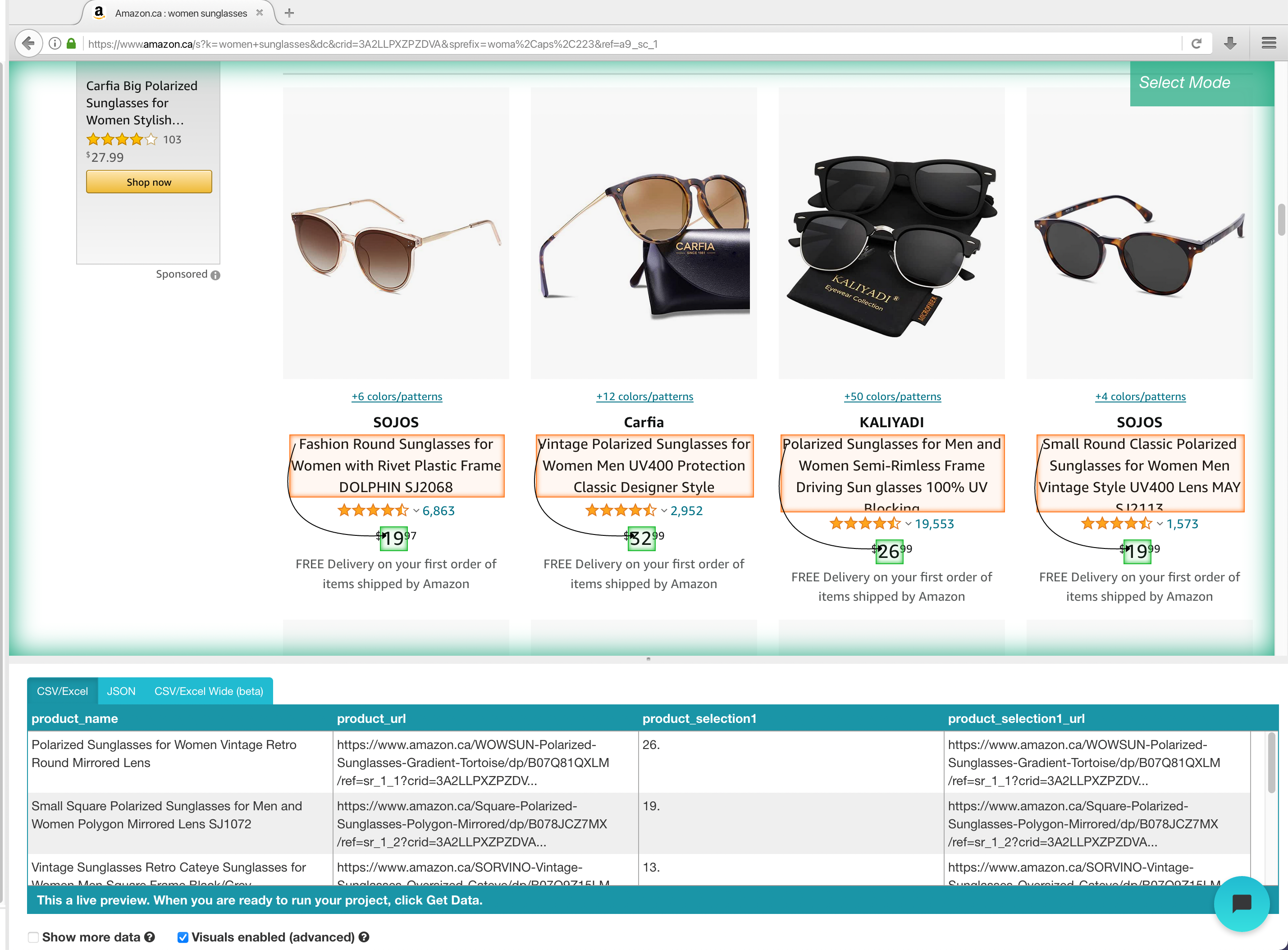
For this example, we are going to show you an easy example of what web scraping can do. For this example, we will be scrapping women's sunglasses on Amazon.
- First, make sure to download and install ParseHub. We will use this web scraper for this project.
- Open ParseHub, click on “New Project” and use the URL from Amazon’s result page. The page will now be rendered inside the app.
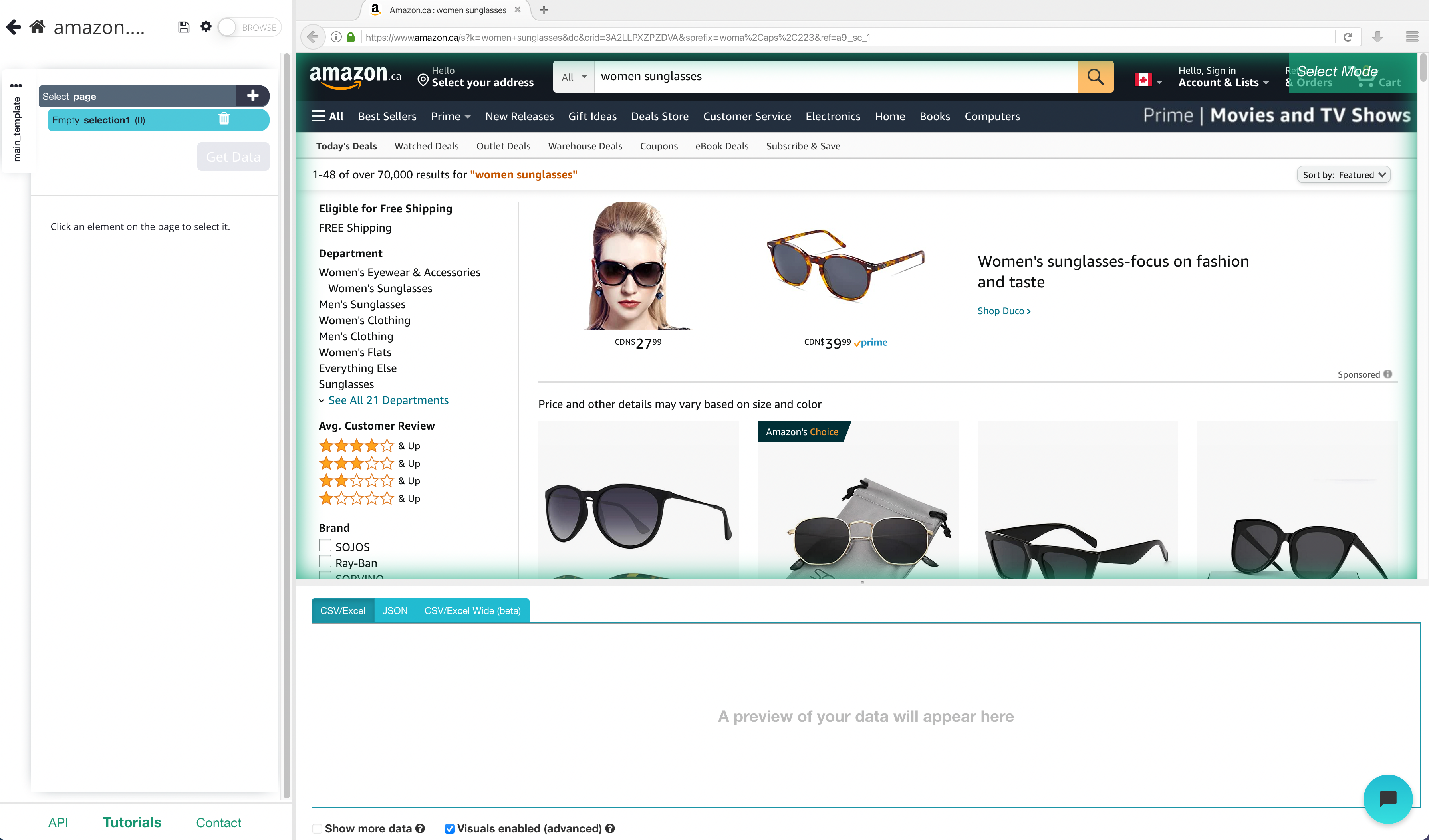
Scraping Amazon Results Page
- Once the site is rendered, click on the product name of the first result on the page. In this case, we will ignore the sponsored listings. The name you’ve clicked will become green to indicate that it’s been selected.
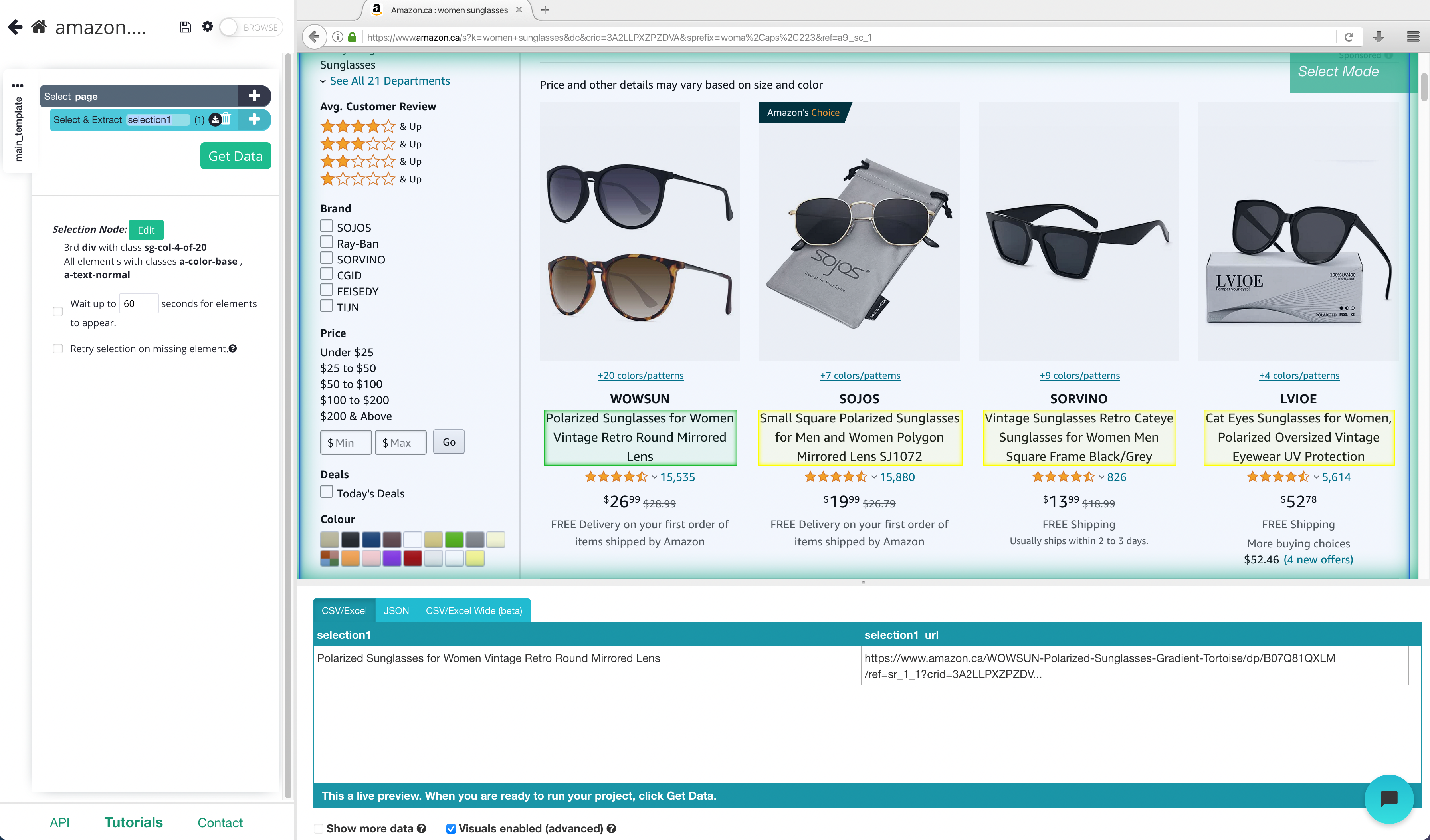
2. The rest of the product names will be highlighted in yellow. Click on the second one on the list. Now all of the items will be highlighted in green (you may need to do this 2-3 times to fully train ParseHub).
3. On the left sidebar, rename your selection to “product”. You will notice that ParseHub is now extracting the product name and URL for each product.
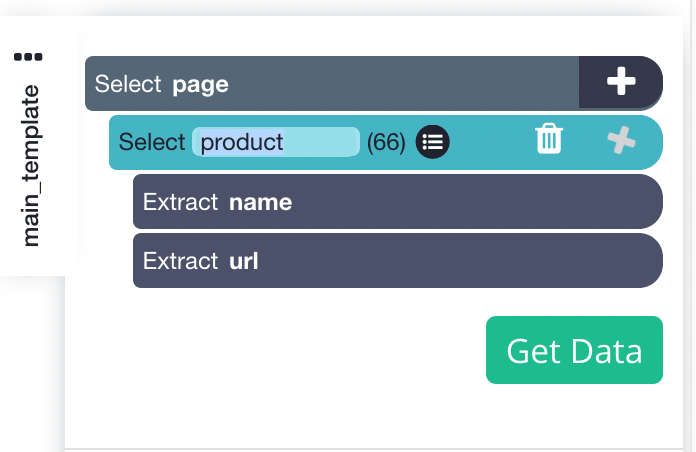
- One the left sidebar, click the PLUS(+) sign next to the product selection and choose the Relative Select command.
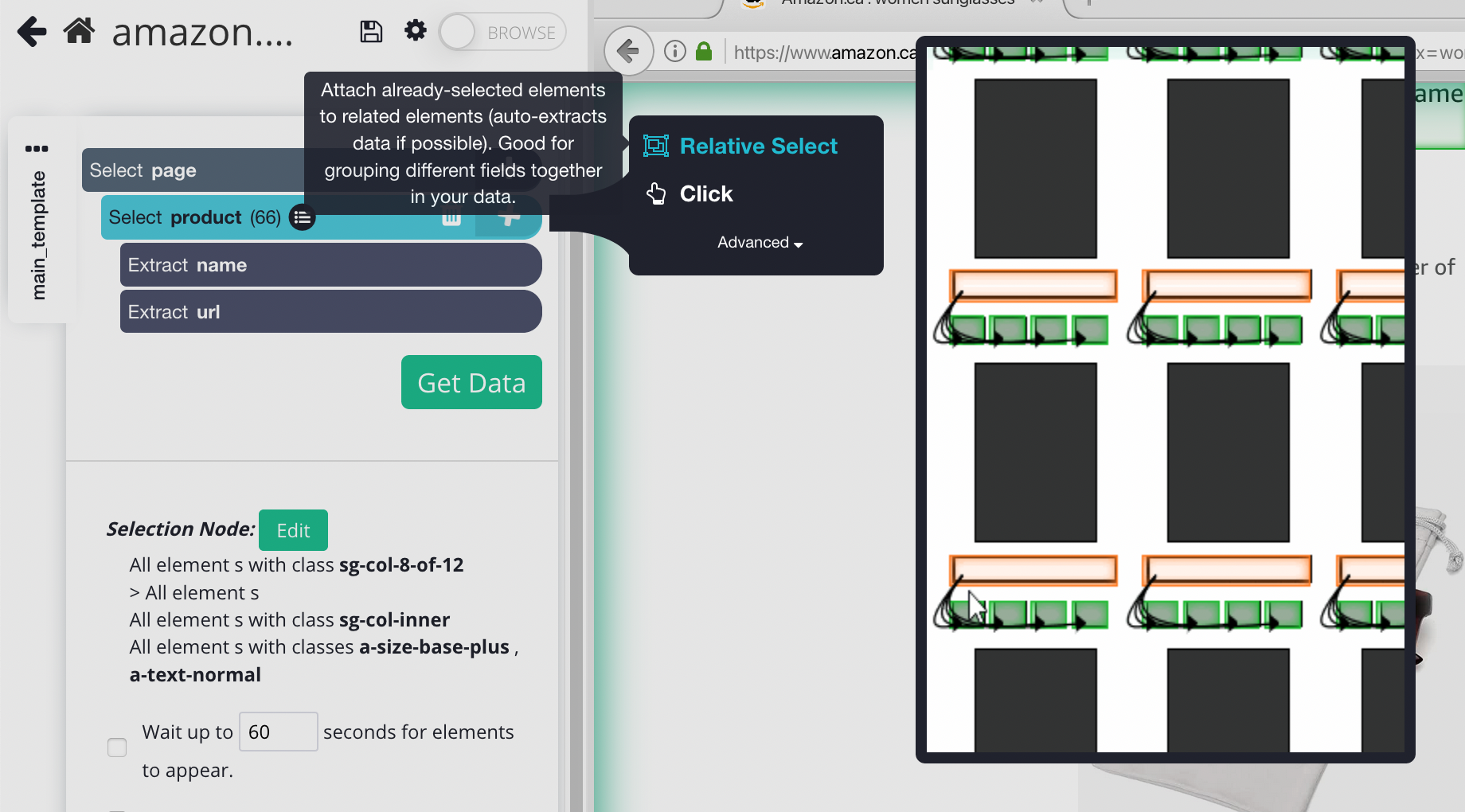
4. Using the Relative Select command, click on the first product name on the page and then on its listing price. You will see an arrow connect the two selections.
5. Expand the new command you’ve created and then delete the URL that is also being extracted by default.
6. Repeat steps 4 through 6 to also extract the product star rating, the number of reviews and product image. Make sure to rename your new selections accordingly.
Adding Pagination
Now, you might want to scrape several pages worth of data for this project. So far, we are only scraping page 1 of the search results. Let’s set up ParseHub to navigate to the next 5 results pages.
- Click on the PLUS(+) sign next to the page selection and choose the Select command. Then select the Next page link at the bottom of the Amazon page. Rename the selection to next.

2. By default, ParseHub will extract the text and URL from this link, so expand your new selection and remove these 2 commands.
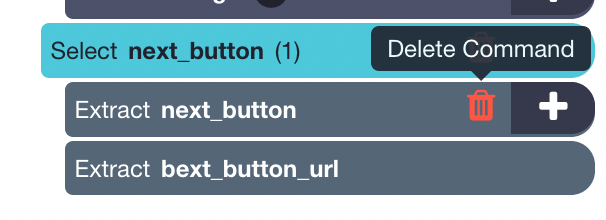
3. Now, click on the PLUS(+) sign of your next selection and use the Click command.

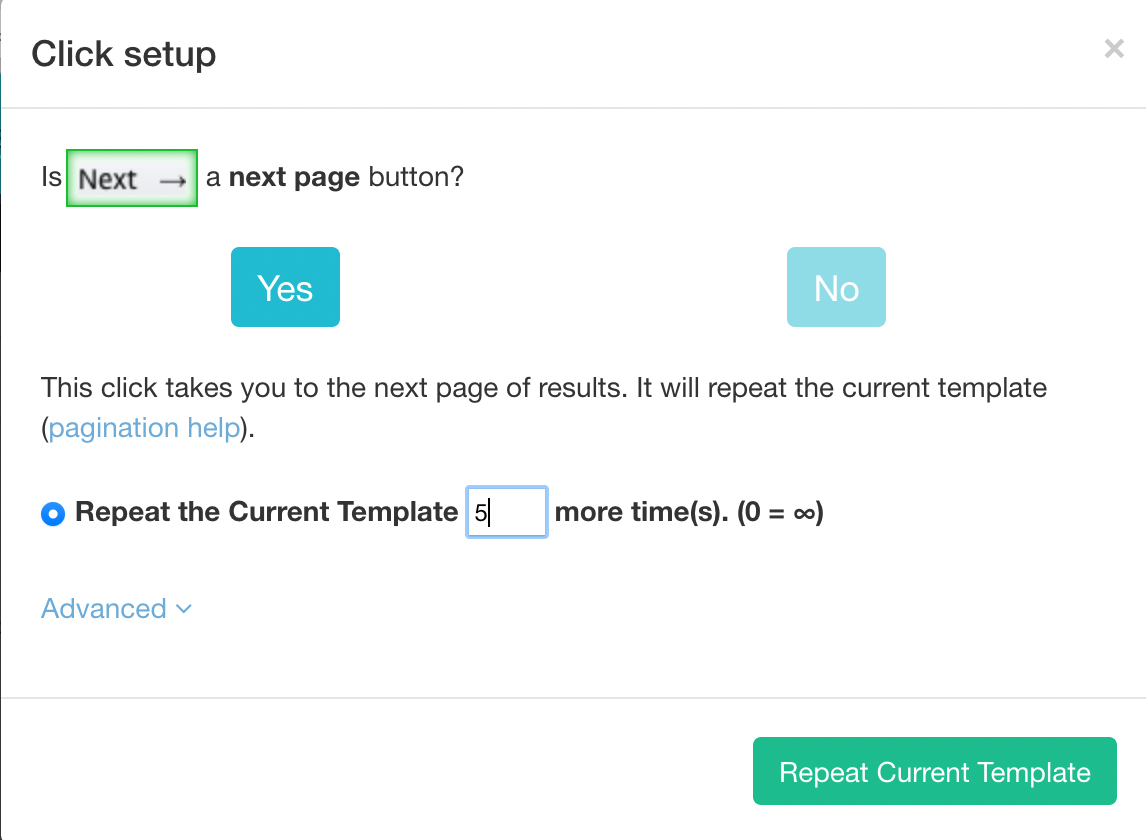
4. A pop-up will appear asking if this is a “Next” link. Click Yes and enter the number of pages you’d like to navigate to. In this case, we will scrape 5 additional pages.
Running and Exporting your Project
Now that we are done setting up the project, it’s time to run our scrape job.
On the left sidebar, click on the Get Data button and click on the Run button to run your scrape. For longer projects, we recommend doing a Test Run to verify that your data will be formatted correctly.
After the scrape job is completed, you will now be able to download all the information you’ve requested as a handy spreadsheet or as a JSON file.
Learn more about web scraping
If you want to learn more about web scraping, we offer free online web scraping courses! You’ll be able to learn more about web scraping and get a certificate of completion once you’re done!
Happy scrapping!