
TechCrunch is a great website to find the latest articles on technology, startups, capital funding and the silicon valley.
Since the articles are based on the tech industry, this can be a great opportunity to get industry insights, investment opportunities, and the can even get the latest news for your website or blog.
We are ParseHub, and we’ll show you how you can scrape TechCrunch articles without coding.
Before we get started, you will need to download and install our free web scraper. It’s easy to use, cloud-based scraping and other features we think you’ll enjoy!
Web scraping TechCrunch Articles
If you would like to follow along with this project, you can use this link here.
Since the TechCrunch article page has a Load More button, we will need to tell ParseHub to not only click on the load more button but to not extract the same articles twice.
We will be using the extract and conditional commands for this project.
- Download and install PareseHub. Click on the new project and button and submit the URL into the text box. The website will now render inside the ParseHub.
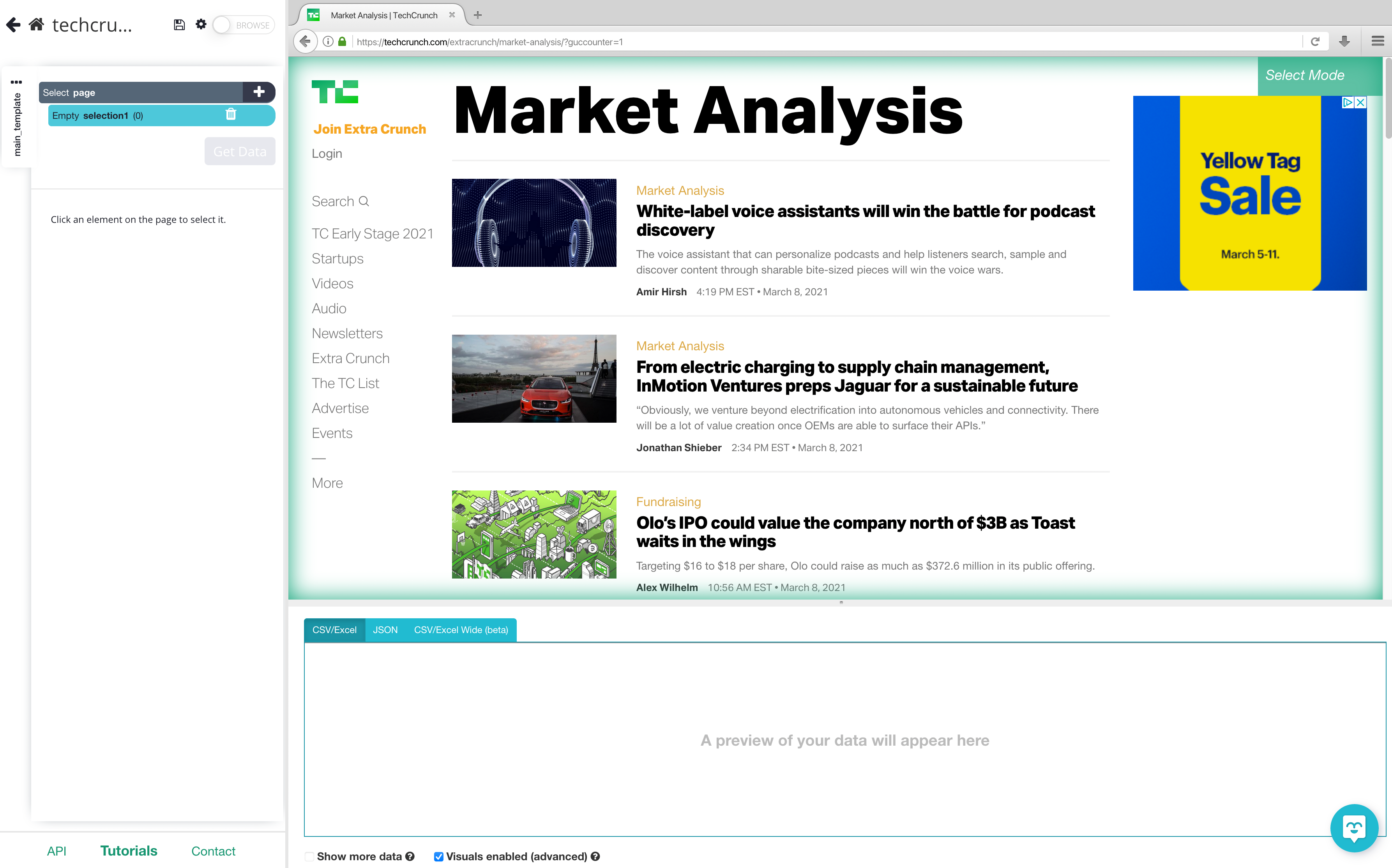
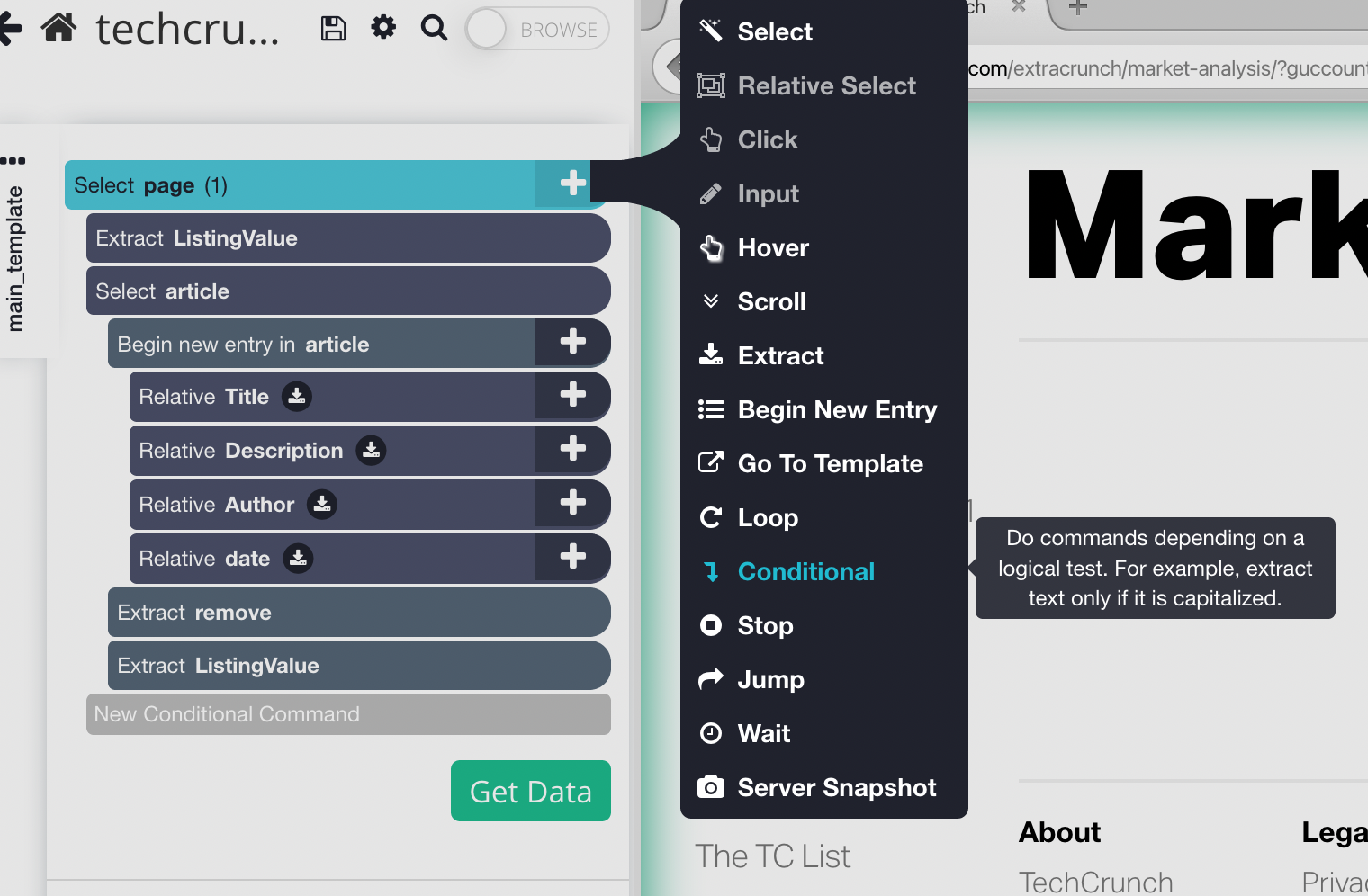
2. Click on the + button next to "Select page", click on advanced, and then choose the Extract command.
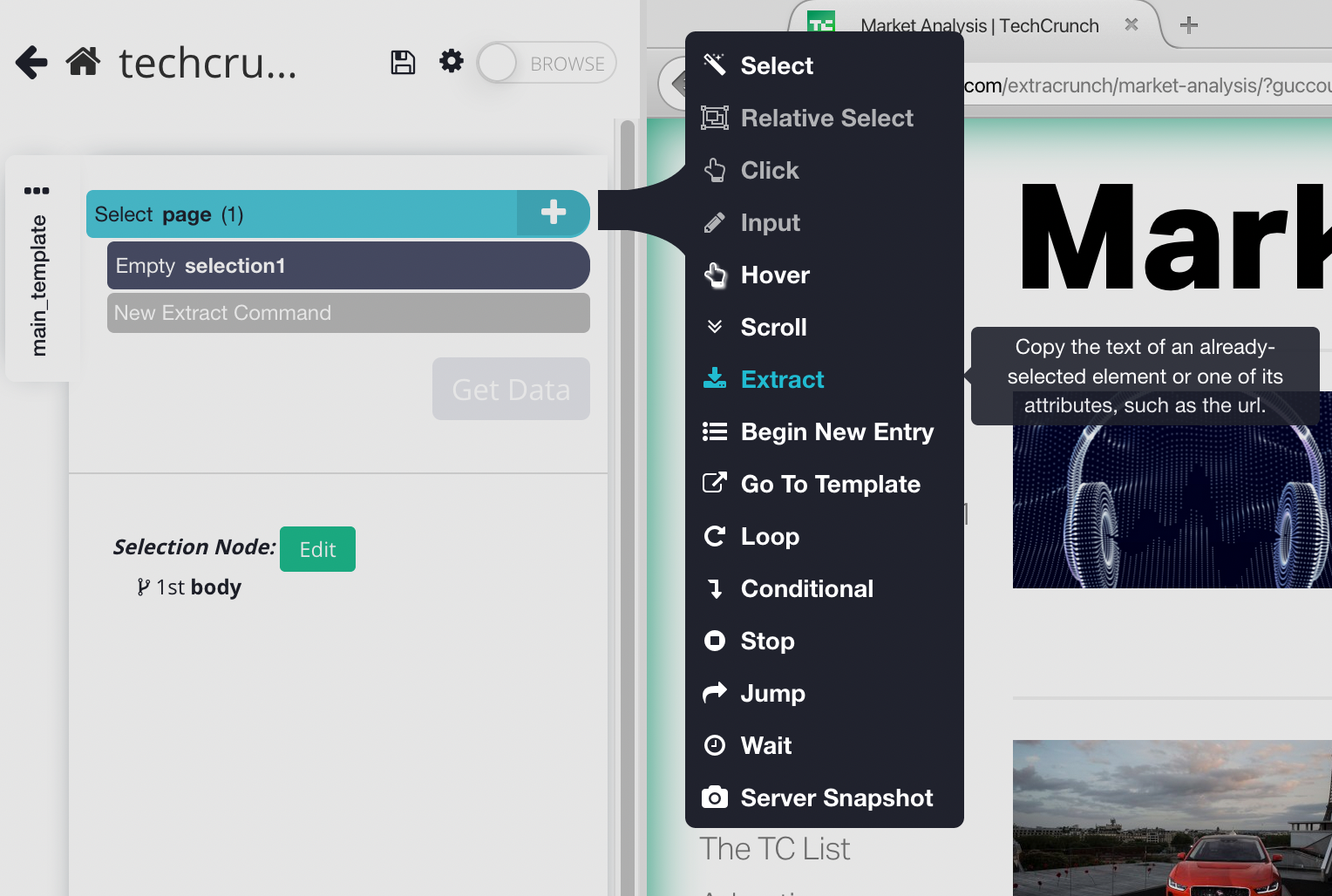
3. Name this command "listingValue", then clear the contents in the extract configuration box and type zero(0) to set the value of the "listingValue" to 0. We will use this value, later on, to check and see if we need to click on the "load more" button or not.
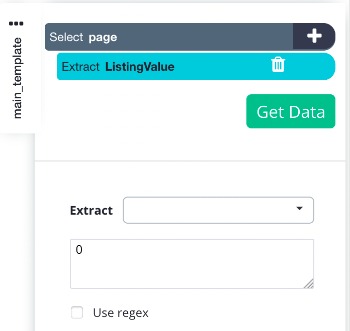
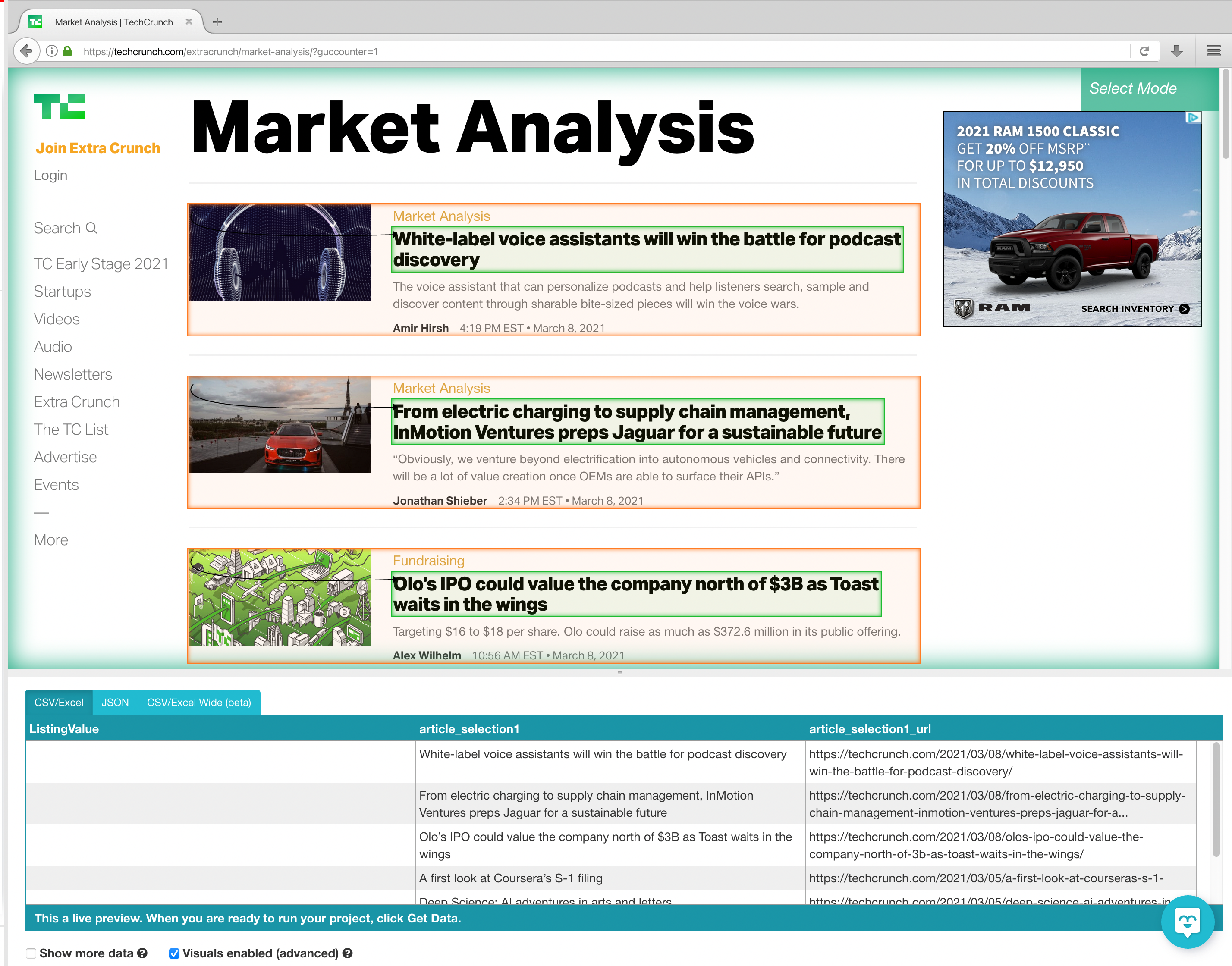
4. Click on the PLUS (+) button next to "Select page" and choose a Select command. Move your cursor onto the first article and hold CTRL key (CMD on Mac) +1 to zoom out on the selection. Now you can select the whole container of the article. Click on the first product to select the container.
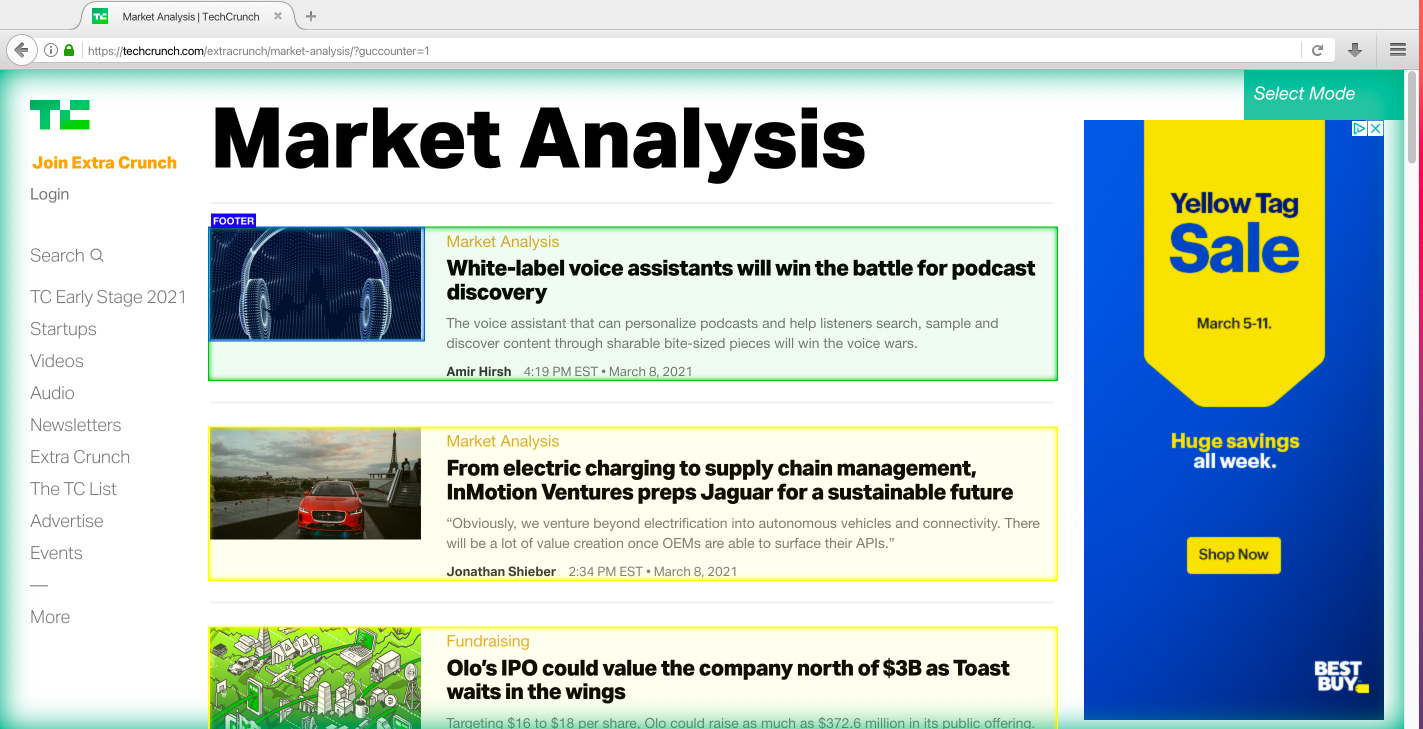
5. ParseHub will now suggest the other articles you want to extract. They will be highlighted in yellow; click on the next one as well to select all the Articles. You may need to do this multiple times to select all of the articles. Let's rename this selection to "article"
6. By selecting all the articles, ParseHub creates a Begin New Entry (list) node which is hidden on the Select container command and extracts the text within the container (name). If you are not interested in the Name you can hover on the extract node and remove it by click on the x button.
7. Expand the Begin New Entry command by clicking on the list icon beside "Select Article".
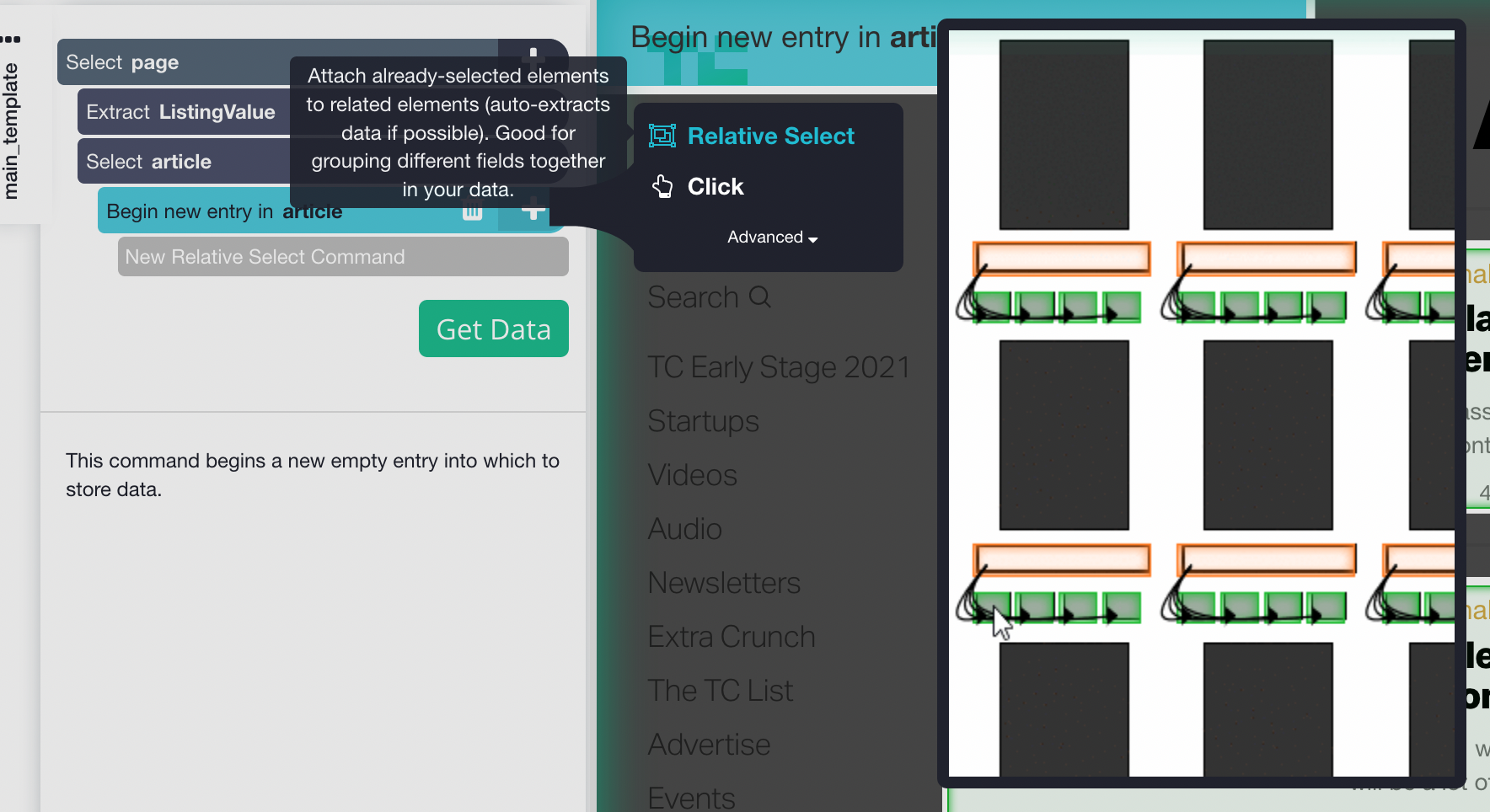
8. We can now select and extract the data from each listing by clicking on the + button next to Begin New Entry (listing) and choosing Relative Select. Click on the container that we selected earlier and use the arrow to select any element you want to extract.
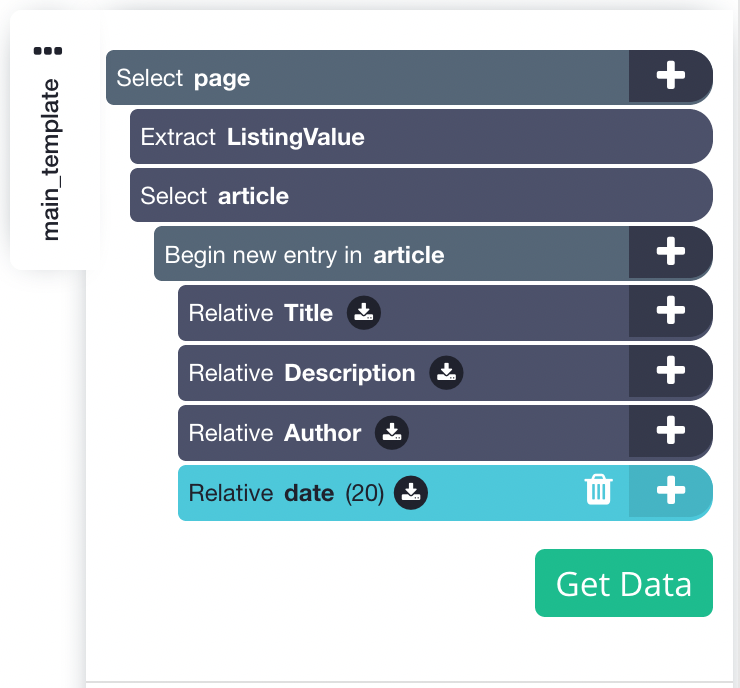
9. Repeat step 8 to extract additional data like description, author and date. your project should look like this for now:
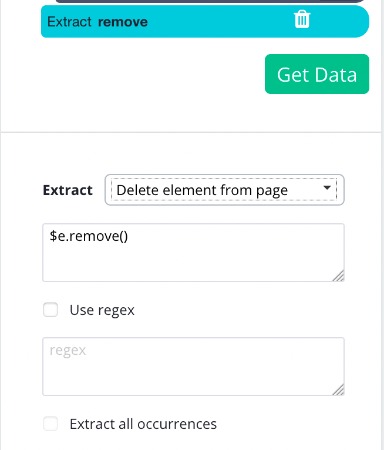
9. Hover over the "Select Article" command and hold the Shift key. Click on the + button that appears and choose an Extract command. Rename this command to "remove", and choose "Delete element from page" from the Extract dropdown menu.
- Hover over the "Select Article" command and hold the Shift key. Click on the + button that appears and choose an Extract command. Rename this command "listingValue" (same as above). This command will execute and set the value of listingValue to 1 once all the products from the list are extracted and removed
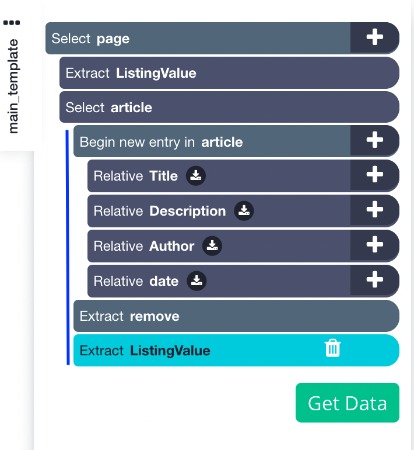
NOTE: Make sure that your Extract commands are not nested within your Begin new entry command! Otherwise, the "listingValue" variable that you are setting equal to 1 will belong to a new scope, and therefore will not be able to be referred to as "listingValue" outside of that scope. The commands should be in line with the Begin new entry command in your command structure.
- Click on the + button next to "Select page", click advanced, and choose a Conditional command.
- In the conditional command just write listingValue. This condition will be true if listingValue equals to 1 (ie. when we are done with the previous steps' commands (extracting and removing)).
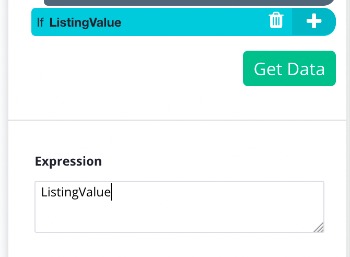
- Click on the + button next to your newly created conditional command, and choose a Select command from the toolbox.
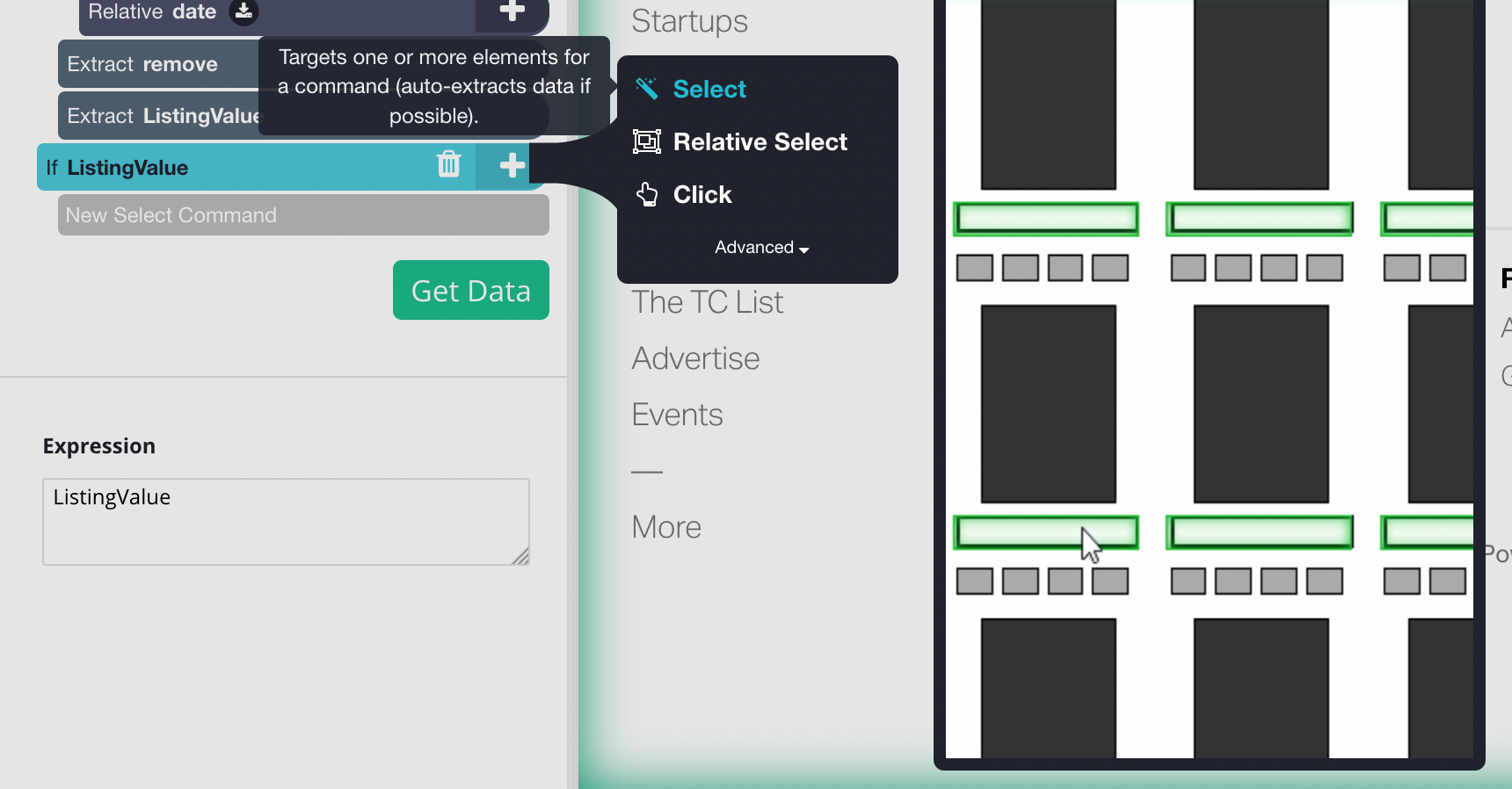
- Use it to select the "load more" button on the website, lets rename the selection to "loadMore"
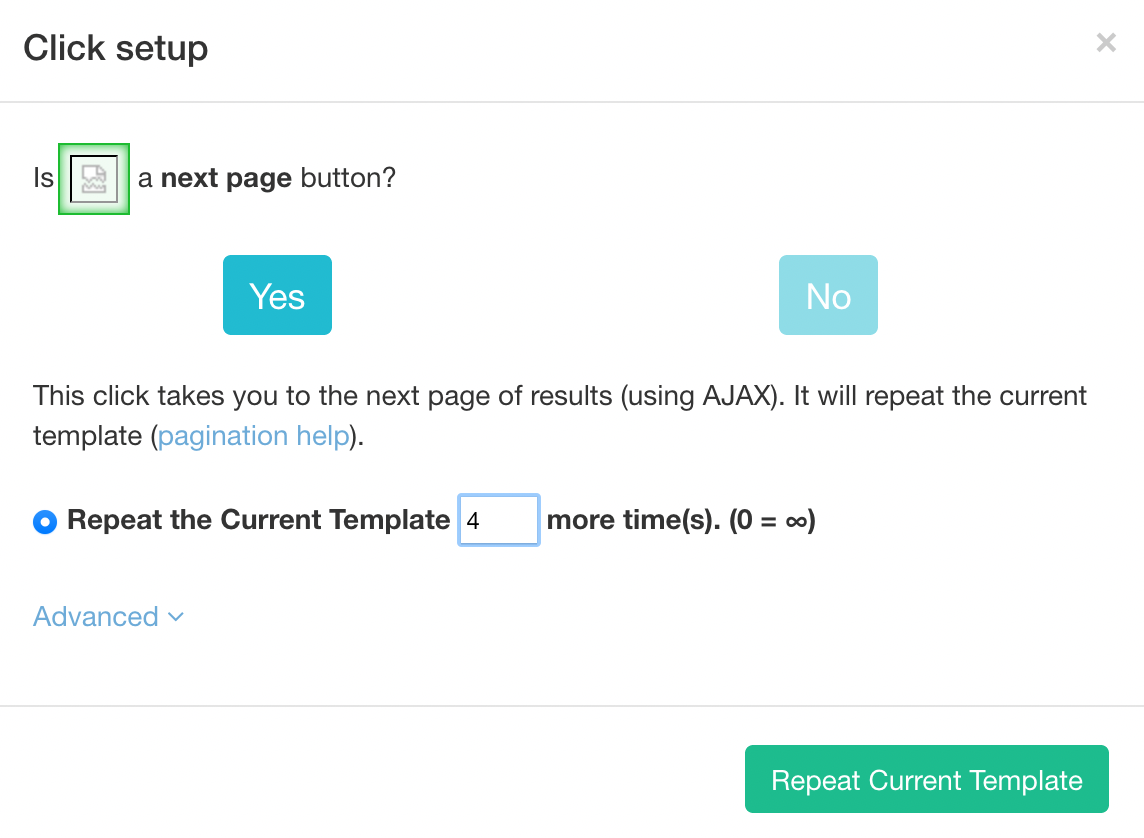
- Click on the + button next to the "Select loadMore" command and add a Click command. In the configuration window that appears, choose the "Yes" when asked if this is a next page button, set the repeats to 4 (or however many pages you want to extract), and repeat the current template. If the listingValue is 1 then the conditional command will proceed and click on the "load more" button to load more products.
Exporting data
It is now time to run your scrape. To do this, click on the green Get Data button on the left sidebar. Here you will be able to test, schedule, or run your scrape job.
For larger projects, we recommend that you always test your job before running it. In this case, we will run it right away.
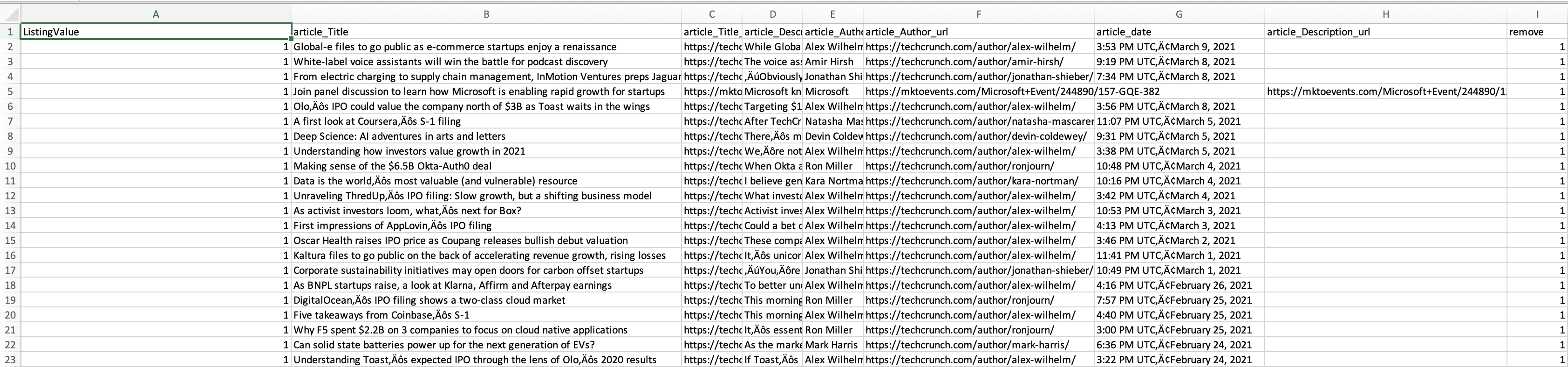
Once your run is completed, you will be able to download it as an Excel or JSON file.
Closing thoughts
Now you know how to extract a website like TechCrunh and using the extract and condition command. You can use this guide to help you with other “load more” pages to extract more data!
What will you scrape next?
Happy Scrapping!